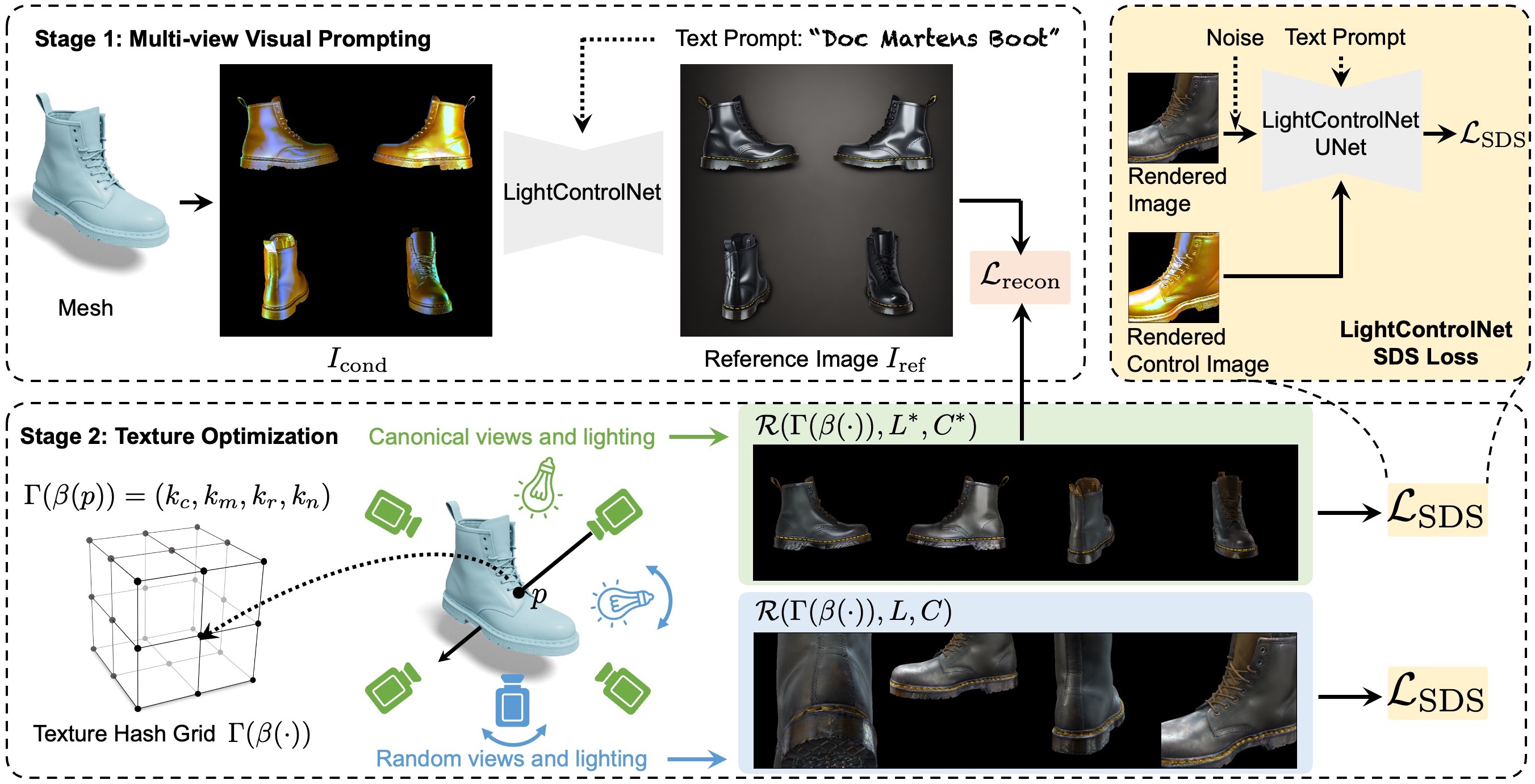
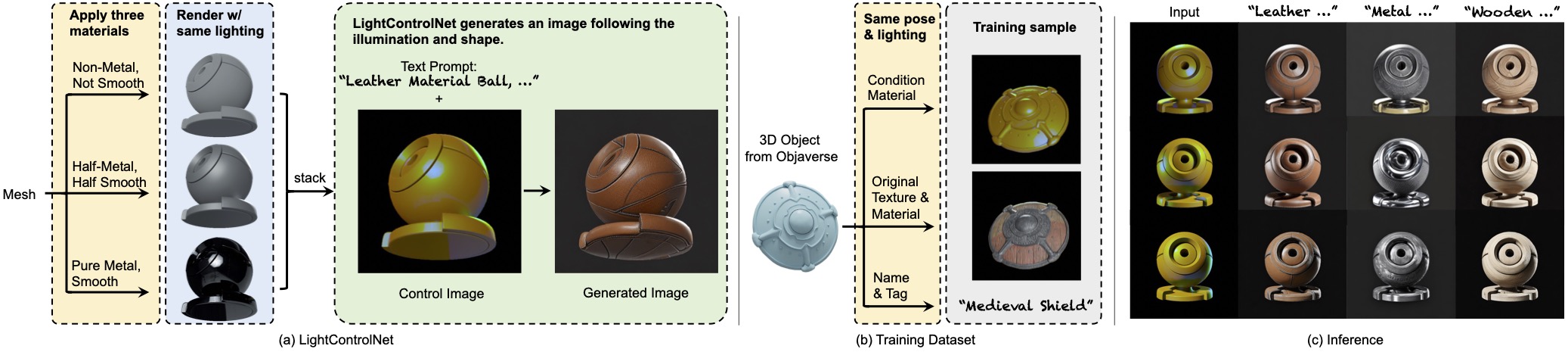
Method Pipeline
Our method efficiently generates relightable textures for an input 3D mesh and text prompt. In stage 1 (top left) we use multi-view visual prompting with our LightControlNet diffusion model to generate four visually consistent canonical views of the mesh under fixed lighting, that we concatenate into a reference image \( I_{\text{ref}} \). In stage 2 we apply a novel texture optimization procedure that uses \( I_{\text{ref}} \) as guidance in combination with a multi-resolution hash-grid representation of the texture \( \Gamma(\beta(\cdot)) \). For each iteration of the optimization we render two batches of images using \( \Gamma(\beta(\cdot)) \) -- one using the canonical views and lighting of \( I_{\text{ref}} \) which we use to compute a reconstruction loss \( \mathcal{L}_{\text{recon}} \) and the other using randomly sampled views and lighting which we use in combination with LightControlNet to compute an SDS loss \( \mathcal{L}_{\text{SDS}} \).